Chromium
进程/线程架构
Chromium 有一个浏览器进程和多个带有沙盒能力的渲染进程。Blink 运行在渲染进程中。安全考虑,一个渲染进程应该只负责一个站点的渲染工作,即站点隔离(Site Isolation)。但实际上,多页签时,渲染进程与站点1对1的关系会占用大量的内存。所以一个页面中的多个 iframe 可能被多个渲染进程渲染,而在不同页面中的多个 iframe 也可能被同一个渲染进程渲染。
Blink 包含一个主线程,多个 Worker 线程,还有一些其他的线程。
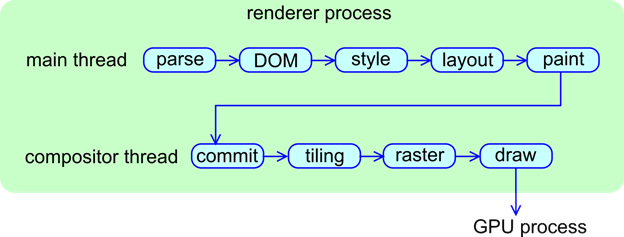
几乎所有重要的工作都运行在主线程上。包括运行 JavaScript,DOM 生成,CSS 样式和布局计算等。
Blink 会为 Web workers、Service workers 创建出独立的线程。虽然运行的都是 JavaScript,但主线程与 worker 线程的运行环境是不共享的,需要通过消息来传递数据。
- 页面(Page),代表一个浏览器页签,一个渲染进程可能负责渲染多个页面。
- 框(Frame),代表主框或者一个 iframe,一个页面至少包含一个框。
- DOMWindow 代表 JavaScript 中的 window 对象,每个框只有一个 DOMWindow。
- Document 代表 JavaScript中的 window.document 对象,每个框只有一个 Document。
- ExecutionContext ,在主线程中抽象一个 Document,在 worker 线程中抽象 WorkerGlobalScope。
Web IDL(Web Interface definition language)
是用于描述浏览器如何实现 Web 平台标准的接口定义语言,通过浏览器对这些标准接口的实现,Web 开发者可以使用 JavaScript 对象来调用这些标准功能。Blink 在实现这些标准的同时,还需要为 V8 中的 JavaScript 提供调用 Blink 的途径,这就是 Web IDL Bindings。例如在 JavaScript 中调用 node.firstChild 时,V8 会调用 V8Node::firstChildAttributeGetterCallback() ,然后进一步调用 Node::firstChild() 。
在实现了通用标准的同时,浏览器还实现了自己特有的功能定义,通用的标准被定义在 the Web IDL spec,而 Blink 自己的定义则被定义在 Blink-specific IDL extended attributes 中。
通常在 idl 文件被构建时,the IDL compiler 会自动为具体的实现类生成 Blink-V8 的绑定。
渲染过程
V8
V8 引擎可以独立运行,也可以运行在任何的 C++ 程序中。一个 V8 的实例被称作 Isolate,每一个 Isolate 都有独立 GC 的堆栈空间。一个 Isolate 中的 JavaScript 对象不能直接访问另一个 Isolate 中的对象。
在 Chrome中,每个渲染进程都有一个 V8 Isolate,所有被同一个渲染进程处理的站点的 JavaScript 代码在同一个 Isolate 中运行。对于 Web worker,每一个 worker 则拥有自己的 Isolate。
在 Isolate 中,存在一个或多个 JavaScript 上下文环境(JavaScript content)。Chrome 为每个 iframe 创建一个 JavaScript 环境。
JavaScript 执行过程
- 从网络或缓存中加载运行的 JavaScript 脚本。
- 分析 JavaScript 脚本,生成用于描述源代码结构化的数据,抽象语法树(Abstract Syntax Tree,AST)。
- 接下来 Ignition 解释器会将 AST 转化成生成体积更小的字节码(bytecode),字节码中的每行指令代表着对寄存器的操作,当字节码生后以后 AST 将会被废弃以节省空间,后续的执行和优化都基于字节码。
- 在解释器执行字节码时,Object Shapes 会试图将代码中对象的类型缓存下来生成 Type Feedback,当访问这些对象时会尝试从缓存中获取,如果找不到再动态查找并更新缓存。 TurboFan 是 V8 中的代码优化编译器,它会评估函数是否需要被进一步优化成机器码以提高性能,需要被优化的函数被编译成 Optimized Code。 但当编译后的函数被发现函数中变量的数据类型与之前缓存的类型不同时,则需要放弃优化的代码回到字节码重新解释执行。
词法分析(lexical analysis)
词法分析是将一系列字符转换成标记(token)的过程。标记是表示源代码的最小单位,将输入的字符流转换成标记的过程被称为标记化(tokenization),在这个过程中,词法分析器还会对这些标记进行分类。常见的标记分类有:
- 标识符(identifier):xx
- 关键字(keyword):if,const,return
- 分隔符(separator):(,}, ;
- 操作符(operator):*,=,>
- 字面量(literal):"xx", true, 1
- 注释(comment):// 单行, /* 多行 */
Scanner 扫描器处在词法分析的第一个阶段,通常基于状态机实现,可以在能识别的标记间不断切换。每种标记可以代表一个字符或由多个字符组成的序列。扫描器只处理utf-16的字符集,所在在扫描器拿到字符之前会有字符集转换的过程。
Evaluator 评估器处在词法分析的第二个阶段,用于将某些带有语义的词定义成值(value),一个语义(lexeme)是标记类型和值的组合。有的标记有值,比如标识符类型的标记,而有的标记没有值,比如分隔符类型的标记。
语法分析(syntactic analysis,也叫 parsing)
语法分析是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。语法分析器(parser)的作用是进行语法检查、并根据输入的单词序列生成带有层次的数据结构(通常是语法分析树、抽象语法树等)
抽象语法树是源代码结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。在分析这个阶段除了要生成AST,还要分析作用域。
V8 有两种分析器:Preparser 和 Full parser。Preparser 分析器可以推迟那些不是立即需要分析的函数以减少代码启动需要的时间。Preparser 只会处理语法分析和一些错误的检查而不会生成抽象语法树。
解释(Interpreting)
解释阶段会将 AST 转换成字节码。得益于即时编译(just-in-time,JIT compilation)技术,包括 V8 在内的现代浏览器 JavaScript 引擎结合了提前编译(AOT)的高性能和解释的灵活性。
代码首先被编译器快速的编译成没有被优化过的机器码,在运行的同时再有选择的将需要优化的代码通过更高级的编译器进行优化再编译。这样做虽然提高了运行速度,但也浪费了资源。其中比较显著的问题是被编译过的机器码会占用大量的内存,即使有的代码可能只会被执行一次。为了解决这些问题,V8 提出了新的 JavaScript 解释器,Ignition。将 AST 先转化成更简洁的字节码。
由 Ignition 生成的字节码会被用于优化的编译器和调试工具当作数据源,当字节码生成以后,抽象语法树就可以被废弃掉以节省内存。在生成字节码的同时,还会在字节码上增加一些元数据,比如源代码的位置和用于执行字节码的处理函数。
累加器(Accumulator)是 V8 中的一个特殊的寄存器,用于存放中间结果。
执行(Execution)。
JavaScript 是一种动态语言,Object.x 可能是简单的属性访问,也可能会调用Getter,甚至可能需要遍历原型链查找。这种动态性需要消耗更多的时间查找属性,会降低运行的速度。为了提高性能,V8 将第一次分析的结果缓存起来,当再次访问属性时直接从缓存中读取。
Object Shapes 也被叫做 Hidden Classes 或 Maps,代表着 JavaScript 对象的结构,属性和元素如何被存储。像 Java 这样的静态语言,一个对象中的属性结构可以在编译前就确定下来,所以这些属性的值可以存储在一段连续的内存空间中,属性间的偏移量可以通过属性的类型计算出来。但由于 JavaScript 的动态性,属性的查找会慢于那些静态语言。为了解决这个问题,V8 使用 Hidden Classes 来描述对象的结构。有了 Hidden Classes,访问 JavaScript 对象的属性时就可以像静态语言那样通过坐标偏移量来快速的定位。
V8 通过内联缓存(Inline Cache)策略优化访问对象的性能。IC 为函数创建名叫反馈向量(FeedBack Vector)的用于存放对象及对象属性的信息。
优化(Optimizing)过程是 V8 利用 TurboFan 编译器将字节码编译成机器码的过程。TurboFan 是一个"Sea-of-nodes"基于图的编译器,它将代码中的数据、流程控制和副作用依赖以节点的方式表达。通过不同阶段的优化,将代码编译成机器码。
回收
JavaScript 中的对象由 Orinoco 回收,其他如 DOM 之类的对象则由 Blink 的垃圾回收器 Oilpan 处理。Orinoco 将存放对象的堆空间分成新、老两个生代。新创建的对象被放在新生代中,存活时间较长的对象则被存放在老生代中。
V8 有着不同的垃圾回收策略:Minor GC(Scavenge)用于新生代,Major GC(Full Mark-Compact)用于整个堆空间。
V8 将整个垃圾回收过程以增量的方式拆分成多个阶段,这些不同阶段的回收过程可以穿插在主线程上其他的工作间隙处。与此同时,用多线程并行的方式让垃圾回收工作在非主线程上进行。
文章参考